

米国特許商標庁(USPTO)が10月17日に公開したエレクトロニック・アーツの特許情報によると、「ゲーム内に“プレイヤーの声から生成した音声”を実装する機能」を構想しているようです。
口調、感情、強調といった非言語的要素までキャプチャ
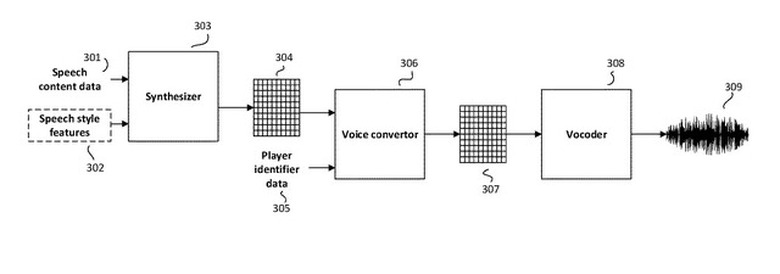
公開された特許は、音声データをシンセサイザーモジュールに入力するシステムの概要を示し、シンセサイザーモジュールによって生成された「話者の音声特徴」と「目的のボイスのソースデータ」を基に、ゲーム内キャラクターのボイスを作成するというもの。プレイしているキャラクターがプレイヤーの声で喋るだけでなく、口調、感情、強調といった非言語的要素のキャプチャも可能だとしています。
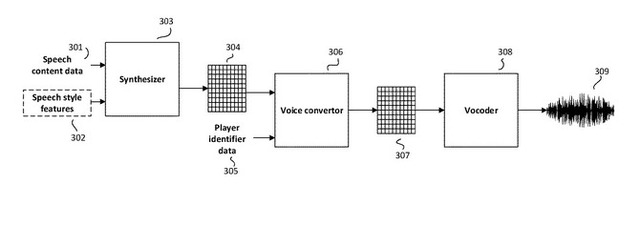
従来の技術では大量の音声サンプルが求められましたが、特許に示された方法を使うことでその数を大幅に減らすことができるとのこと。特許情報の後半では、現代のビデオゲームの多くでプレイヤーキャラクターを作成する機能が提供されていることにも触れています。
画期的な技術だが、音声データ量の削減による懸念も

自分の音声をゲームに反映できるこの技術は、ゲームキャラとの会話も実現できるとすればなかなか画期的。しかし、海外メディアなどでは開発中に必要な音声データ量の削減を目的としているとの見方もあります。ゲーム業界でも「AI音声の導入」というトピックが議論されているところですが、EAの新たな構想は今後も注目を集めそうです。


